
Questa esaustiva introduzione sul funzionamento interno dei motori WebKit e Gecko è il frutto del duro lavoro di ricerca svolto dalla sviluppatrice israeliana Tali Garsiel. Nel corso di alcuni anni ha studiato i dati pubblici sul funzionamento dei browser, investendo molto tempo ad indagare direttamente nel loro codice sorgente, la sua premessa :
Negli anni del dominio di IE al 90% di dIffusione non c’era altra scelta se non pensare al browser come una “scatola nera”, ma adesso, con i browser open source che posseggono più della metà dello share di utilizzo, è il momento buono per sbirciare sotto il cofano del motore e vedere cosa c’è dentro un web browser. Ebbene, ciò che si trova all’interno sono milioni di righe di C++ …
La presente traduzione italiana curata da me si basa sulla versione pubblicata su HTML5rocks.com, adattata da Paul Irish, il quale aggiunge a sua volta :
In qualità di sviluppatore web, apprendere le operazioni interne del browser ti aiuterà a compiere decisioni migliori e comprendere le ragioni alla basse di molte buone prassi di sviluppo. Nonostante la copiosa lunghezza del documento, vale la pena investire del tempo per scavarvi affondo; è garantito che sarai felice di averlo fatto.
La versione originale è disponibile sul sito dell’autrice, al seguente indirizzo : http://taligarsiel.com/Projects/howbrowserswork1.htm .
Introduzione
I web browser sono i software più utilizzati. In questa introduzione, spiegherò come funzionano dietro le quinte. Vedremo cosa accade quando digiti google.com nella barra degli indirizzi finché non appare la pagina di Google nella schermata del browser.
I browser di cui parleremo
Ci sono cinque browser principali usati oggigiorno su desktop : Chrome, Internet Explorer, Firefox, Safari e Opera. Sul mobile, i browser principali sono Android Browser, iPhone, Opera Mini ed Opera Mobile, UC Browser, il browser di Nokia S40/S60 e Chrome, i quali sono tutti, fatta eccezione per Opera, basati su WebKit. Proporrò degli esempi tratti dai browser open source Firefox e Chrome, e Safari (che è parzialmente open source). Stando alle statistiche di StatCounter (aggiornate a Giugno 2013) Chrome, Firefox e Safari costituiscono circa il 71% degli utenti globali per l’uso di browser su desktop. Su mobile, Android Browser, iPhone e Chrome costituiscono circa il 54% di utilizzatori.
Le funzionalità principali dei browser
La funzione principale di un browser è di presentare la risorsa web prescelta, richiedendola da un server e mostrandola nella finestra del browser. La risorsa è solitamente un documento HTML, ma può essere anche un PDF, un’immagine, o un altro tipo di contenuto. L’ubicazione della risorsa viene specificata dall’utente tramite URI (Uniform Resource Identifier). Il modo in cui la maggior parte dei browser interpreta e mostra i file HTML è dichiarato nelle specifiche HTML e CSS. Queste specifiche sono manutenute dall’organizzazione del W3C (World Wide Web Consortium), che è una organizzazione per gli standard del web. Per anni i browser si sono conformati in parte alle specifiche sviluppando le proprie estensioni. Questo ha causato gravi problemi di compatibilità per gli sviluppatori web. Oggi la maggior parte dei browser più o meno si conforma alle specifiche. Le interfacce utente del browser hanno molto in comune tra loro. Tra gli elementi dell’interfaccia condivisi figurano :
- La barra degli indirizzi per inserire una URI
- Tasti Avanti e Indietro
- Opzioni per i preferiti
- Tasti Ricarica e Stop per controllare il caricamento del documento corrente.
- Tasto Home che riporta la pagina alla propria pagina iniziale.
Stranamente, l’interfaccia utente del browser non è definita in nessuna specifica formale, deriva semplicemente dalla buona prassi che si è formata tramite anni di esperienza con i browser che si imitavano a vicenda. Le specifiche HTML5 non definiscono gli elementi di UI che un browser deve avere, ma elenca alcuni elementi comuni. Tra questi la barra degli indirizzi, la barra di stato e degli strumenti. Ci sono, ovviamente, caratteristiche uniche e specifiche a ciascun browser come il download manager di Firefox.
La struttura di alto livello del browser
I componenti principali del browser sono :
- L’interfaccia utente : include la barra degli indirizzi, tasti indietro/avanti, menu bookmark etc. Ogni parte visibile del browser eccetto la finestra dove viene visualizzata la pagina richiesta.
- Il motore del browser : ordina le azioni tra la UI e il motore di rendering.
- Il motore di rendering : responsabile per la visualizzazione dei contenuti richiesti. Ad esempio se il contenuto richiesto è HTML, il motore di rendering analizza l’HTML e il CSS e mostra il contenuto analizzato sullo schermo.
- Networking : per le chiamate di rete come le richieste HTTP, usando diverse implementazioni per diverse piattaforme dietro un interfaccia agnostica alla piattaforma usata.
- UI backend : usata per disegnare widgets basilari come le combo box e le finestre. Questo backend espone un interfaccia generica che non è specifica di una piattaforma. In profondità utilizza metodi della UI del sistema operativo.
- Interprete JavaScript : usato per analizzare ed eseguire il codice JavaScript.
- Memorizzazione Dati : è un livello di persistenza. Il browser può avere necessità di salvare diverse tipologie di dati localmente, come i cookie. I browser inoltre supportano meccanismi di memorizzazione come localStorage, IndexedDB, WebSQL e FileSystem.
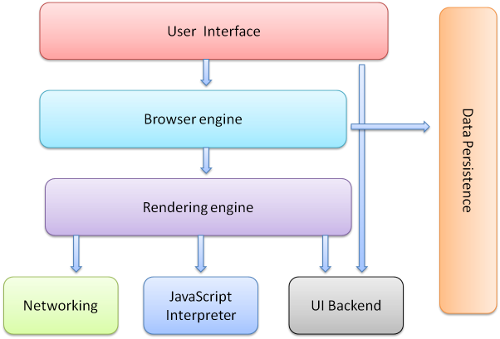
È importante notare che i browser come Chrome eseguono istanze multiple del motore di rendering : uno per ciascuna tab. Ogni tab è eseguita in un processo separato.
Il motore di rendering
La responsabilità del motore di rendering è … renderizzare, ovvero mostrare il contenuto richiesto nella finestra del browser. Il motore di rendering può mostrare nativamente documenti HTML ed XML ed immagini. Può mostrare anche altri tipi di dati tramite plugin ed estensioni; per esempio, mostrare documenti PDF tramite un plugin PDF viewer. Tuttavia, in questo capitolo ci concentreremo sul caso d’uso principale : mostrare HTML ed immagini formattate usando il CSS.
Motori di rendering
Diversi browser usano diversi motori di rendering : Internet Explorer usa Trident, Firefox usa Gecko, Safari usa WebKit. Chrome ed Opera (rispettivamente dalla versione 28 e 15) usano Blink, un fork di WebKit. WebKit è un motore di rendering open source che è nato come motore per la piattaforma Linux ed è stato modificato da Apple per supportare il Mac e Windows. Consulta webkit.org per maggiori dettagli.
Il flusso principale
Il motore di rendering inizierà ad ottenere i contenuti del documento richiesto dal layer Networking. Il trasferimento avviene solitamente in pacchetti di 8kB. Successivamente, il flusso base del motore di rendering procede in questo modo :  Il motore di rendering inizierà l’analisi (parsing) del documento HTML per convertirne gli elementi in nodi del DOM da inserire in un albero di contenuti (content tree). Il motore procede quindi all’analisi dei dati sugli stili, sia nei CSS esterni che degli stili inline del documento. Le informazioni sugli stili insieme alle istruzioni visuali dell’HTML vengono usate per costruire un’altro albero : l’albero di render (render tree). L’albero di render contiene rettangoli con attributi visuali quali colori e dimensioni. I rettangoli sono disposti nel giusto ordine per essere mostrati sullo schermo. Dopo la costruzione dell’albero di render segue il processo di disposizione (layout). Consiste nell’attribuire ad ogni nodo le coordinate precise del punto dello schermo in cui deve apparire. Il passaggio successivo è il processo di pittura (painting) : l’albero di render viene percorso ed ogni nodo viene pitturato sullo schermo usando il livello di UI backend. È importante comprendere che questo processo è graduale. Per una migliore esperienza utente, il motore di rendering cercherà di mostrare i contenuti sullo schermo il prima possibile. Non aspetterà che tutto l’HTML sia stato analizzato prima di iniziare a costruire e disporre l’albero di render. Parti del contenuto verranno analizzate e visualizzate, mentre il processo avanza con il resto dei contenuti che continua ad arrivare dalla rete.
Il motore di rendering inizierà l’analisi (parsing) del documento HTML per convertirne gli elementi in nodi del DOM da inserire in un albero di contenuti (content tree). Il motore procede quindi all’analisi dei dati sugli stili, sia nei CSS esterni che degli stili inline del documento. Le informazioni sugli stili insieme alle istruzioni visuali dell’HTML vengono usate per costruire un’altro albero : l’albero di render (render tree). L’albero di render contiene rettangoli con attributi visuali quali colori e dimensioni. I rettangoli sono disposti nel giusto ordine per essere mostrati sullo schermo. Dopo la costruzione dell’albero di render segue il processo di disposizione (layout). Consiste nell’attribuire ad ogni nodo le coordinate precise del punto dello schermo in cui deve apparire. Il passaggio successivo è il processo di pittura (painting) : l’albero di render viene percorso ed ogni nodo viene pitturato sullo schermo usando il livello di UI backend. È importante comprendere che questo processo è graduale. Per una migliore esperienza utente, il motore di rendering cercherà di mostrare i contenuti sullo schermo il prima possibile. Non aspetterà che tutto l’HTML sia stato analizzato prima di iniziare a costruire e disporre l’albero di render. Parti del contenuto verranno analizzate e visualizzate, mentre il processo avanza con il resto dei contenuti che continua ad arrivare dalla rete.
Esempi del flusso principale
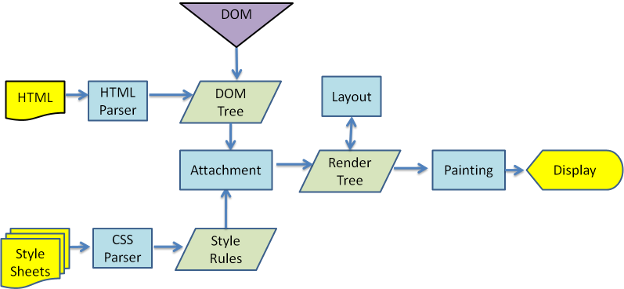
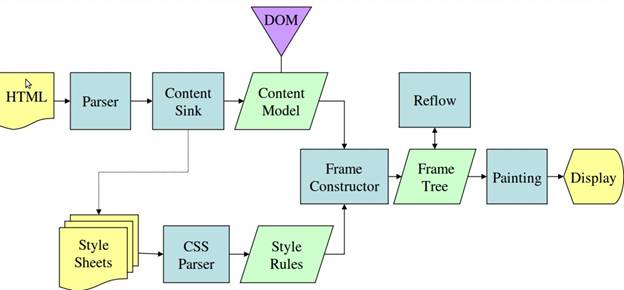
Le figure illustrano come nonostante WebKit e Gecko utilizzino terminologie leggermente diverse, il processo è basilarmente lo stesso. Gecko chiama l’albero degli elementi formattati visualmente “Frame tree“. Ogni elemento è un frame. WebKit usa il termine “Render tree” ed è costituito da “Render objects“. WebKit usa il termine “Layout” per la disposizione degli elementi, mentre Gecko lo chiama “Reflow“. “Attachment” è il termine che usa WebKit per indicare il collegamento dei nodi del DOM alle informazioni visuali per creare l’albero di rendering. Un’altra piccola differenza non semantica è che Gecko ha un livello ulteriore che si frappone tra l’HTML e l’albero del DOM, si chiama “content sink” ed è una fabbrica di creazione di elementi del DOM. Ora discuteremo di ciascuna parte del flusso.
Analisi e costruzione dell’albero del DOM
Dato che l’analisi è un processo molto importante all’interno di un motore di rendering, approfondiremo l’argomento. Iniziamo con una piccola introduzione sul parsing.
Nozioni sui parser
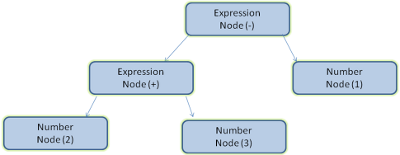
Eseguire il parsing, ovvero l’analisi, di un documento significa tradurlo in una struttura che il codice possa utilizzare. Il risultato dell’analisi è generalmente un’alberatura di nodi che rappresentano la struttura del documento. Questo è chiamato albero di analisi (parse tree) oppure albero sintattico (syntax tree). Per esempio, un’analisi dell’espressione 2 + 3 -1 potrebbe restituire il seguente albero :
Grammatica
L’analisi è basata sulle regole sintattiche a cui obbedisce il documento : la lingua o il formato in cui è stato scritto. Ogni formato che deve essere analizzato deve avere una grammatica deterministica che consista di vocabolario e regole sintattiche. Queste caratteristiche identificano una grammatica libera dal contesto. Le lingue umane non rientrano in questa categoria e per questo motivo non possono essere analizzate con le tecniche di analisi convenzionali.
Combinazione Parser-Lexer
L’analisi può essere separata in due sottoprocessi : analisi lessicale ed analisi sintattica. L’analisi lessicale è il processo di scomposizione dei dati iniziali in frammenti (token). I frammenti sono i vocaboli del linguaggio : la collezione di blocchi costruttori validi. Nei linguaggi umani consiste nell’insieme di parole che appaiono nel dizionario di una data lingua. L’analisi sintattica è l’applicazione delle regole sintattiche del linguaggio. I parser solitamente dividono il lavoro tra due componenti : il lessicatore (lexer), a volte chiamato frammentatore (tokenizer), che si occupa di spezzettare i dati di ingresso in frammenti validi, ed il parser che si occupa di costruire l’alberatura di analisi confrontando la struttura del documento con le regole sintattiche del suo linguaggio. Il lessicatore sa come rimuovere caratteri irrilevanti quali spazi vuoti e ritorni a capo.
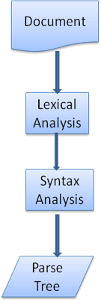
Il processo di analisi è iterativo. Il parser solitamente chiederà al lessicatore un nuovo frammento e cercherà di farlo corrispondere con una delle regole sintattiche del linguaggio. Se una regola corrisponde, un nodo corrispondente al frammento verrà aggiunto all’albero di analisi ed il parser chiederà di nuovo un altro frammento. Se nessuna regola corrisponde, il parser memorizzerà il frammento internamente, e continuerà a chiedere nuovi frammenti finché non verrà trovata una regola che corrisponda a tutti i frammenti memorizzati internamente. Se nessuna regola viene trovata il parser lancerà un eccezione. Ciò significa che il documento non era valido e conteneva degli errori sintattici.
Traduzione
In molti casi l’albero di analisi non è il prodotto finale. L’analisi è usata nella traduzione, ovvero nella trasformazione del documento iniziale in un altro formato. Un esempio è la compilazione. Il compilatore che trasforma il codice sorgente in codice macchina prima analizza il codice in entrata creando un alberatura di analisi e successivamente lo traduce in un documento di codice macchina.
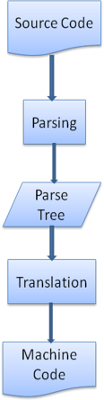
Esempio di parsing
Prima abbiamo costruito l’albero d’analisi di un’espressione aritmetica. Proviamo a definire un semplice linguaggio matematico per capire il processo di analisi. Vocabolario : il nostro linguaggio può includere interi, segno più e segno meno. Sintassi :
- I blocchi costruttori della sintassi del nostro linguaggio sono espressioni, termini ed operazioni.
- Il nostro linguaggio può includere un numero infinito di espressioni.
- Un’espressione è definita come un “termine” seguita da un “operazione” seguita da un altro termine.
- Un operazione è un frammento più o un frammento meno.
- Un termine è un frammento intero oppure un’espressione
Analizziamo come sorgente 2 + 3 - 1. La prima parte di stringa che corrisponde ad una regola è il 2 : stando alla regola n°5 è un termine. La seconda corrispondenza è 2 + 3, ovvero è un’espressione perché corrisponde alla regola n°3, un termine seguito da un operazione seguito da un altro termine. La prossima corrispondenza viene trovata solo alla fine dell’elaborazione. 2 + 3 - 1 è un’espressione perché sappiamo che 2 + 3 è un termine, quindi abbiamo un termine seguito da un altro termine. 2 + + non corrisponderà a nessuna regola perché non è un sorgente valido.
Definizioni formali di vocabolario e sintassi
Il vocabolario è generalmente definito tramite espressioni regolari. Per esempio il nostro linguaggio sarà definito come segue :
|
1 2 3 |
INTEGER: 0|[1-9][0-9]* PLUS: + MINUS: - |
Come si può constatare, gli interi sono definiti per mezzo di espressioni regolari. La sintassi è solitamente definita in un formato chiamato BNF. Il nostro linguaggio sarà definito come segue :
|
1 2 3 |
expression := term operation term operation := PLUS | MINUS term := INTEGER | expression |
Avevamo accennato al fatto che un linguaggio può essere analizzato dai parser normali se la sua grammatica è libera dal contesto. Una definizione intuitiva di grammatica libera dal contesto è una grammatica che possa essere interamente espressa in linguaggio BNF. Per una definizione formale consulta l’articolo di Wikipedia sulla grammatica libera dal contesto.
Tipologie di parser
Ci sono due tipi di parser : parser top-down e parser bottom-up. Una spiegazione intuitiva è che top-down consiste nell’esaminare la struttura di alto livello della sintassi per provare a cercare una regola che corrisponda. Bottom-up consiste nel cominciare dal sorgente in entrata e trasformarlo gradualmente in regole sintattiche, iniziando dalle regole di basso livello finché non vengono incontrate quelle di alto livello. Vediamo come i due diversi tipi di parser analizzano il nostro esempio. Il parser top-down inizierà dalle regole di alto livello : identificherà 2 + 3 come espressione, poi identificherà 2 + 3 - 1 come espressione (il processo di identificazione delle espressioni si evolve, trovando le altre regole, ma il punto di inizio sono le regole di alto livello). Il parser bottom-up analizzerà il codice in ingresso finché non viene a corrispondere con una regola. A quel punto rimpiazzerà l’elemento di input con la regola. Il processo andrà avanti fino alla fine del codice. Le espressioni individuate parzialmente verrano inserite nella coda di operazioni del parser.
| Stack | Input |
|---|---|
| 2 + 3 – 1 | |
| term | + 3 – 1 |
| term operation | 3 – 1 |
| expression | – 1 |
| expression operation | 1 |
| expression | – |
La tipologia bottom-up è anche detta shift-reducer, perché il sorgente è spostato verso destra (immagina un puntatore che indica l’inizio della riga ed inizia a scorrere verso destra i singoli caratteri) e viene gradualmente ridotto a regole sintattiche.
Generazione automatica dei parser
Ci sono degli strumenti che possono generare dei parser. Gli si da in pasto la grammatica del proprio linguaggio, il suo vocabolario e la sua sintassi, e genera un parser funzionante. Creare un parser richiede una conoscenza approfondita del meccanismo di analisi e non è facile crearne uno ottimizzato manualmente, quindi i generatori di parser possono essere molto utili. WebKit utilizza due generatori di parser molto conosciuti : Flex per generare il lessicatore e Bison per il parser principale (potresti averli incontrati sotto i nomi di Lex e Yacc).
Parser HTML
Il compito del parser HTML è di trasformare il codice sorgente del documento in un alberatura d’analisi.
La definizione della grammatica HTML
Il vocabolario e la sintassi dell’HTML sono definite nelle specifiche create dall’organizzazione del W3C.
Non è una grammatica libera dal contesto
Come abbiamo visto nell’introduzione ai parser, la sintassi della grammatica può essere definita formalmente usando formati come il BNF. Sfortunatamente nessuno degli argomenti convenzionali relativi ai parser può essere applicato all’HTML (saranno invece discussi per il CSS e il JavaScript che li adottano). L’HTML non può essere facilmente definito in una grammatica libera dal contesto necessaria ad un parser. C’è una struttura formale per definire gli HTML-DTD (Document Type Definition), ma non è una grammatica libera dal contesto. All’inzio sembra strano : l’HTML è molto simile all’XML. Ci sono numerosi parser XML in circolazione. C’è anche una variante XML dell’HTML, ovvero l’XHTML, quindi dove stà la grande differenza? La differenza è che l’approccio dell’HTML è molto “clemente“ : ti permette di omettere alcuni tag (che vengono però aggiunti implicitamente), o alcune volte permette di omettere l’inzio o la fine di alcuni tag e via discorrendo. Generalmente è una sintassi “leggera”, contrariamente alla sintassi rigida ed obbligatoria dell’XML. Questo apparentemente piccolo dettaglio costituisce una differenza abissale. Da una parte questa è la ragione principale che ha reso l’HTML così popolare : perdona i tuoi errori e rende la vita più facile agli sviluppatori web, dall’altra rende molto difficile il compito di scrivere una grammatica formale. Quindi recapitolando, l’HTML non può essere analizzato facilmente dai parser convenzionali, poichè la sua grammatica non è libera dal contesto. L’HTML non può essere analizzato dai parser XML.
HTML DTD
La definizione del linguaggio HTML avviene in formato DTD. Questo formato è usato per definire i linguaggi della famiglia SGML. Il formato contiene definizioni degli elementi consentiti, i loro attributi e gerarchie. Come abbiamo visto, l’HTML DTD non forma una grammatica libera dal contesto. Ci sono alcune variazioni del DTD. La modalità strict è conforme solo alle specifiche ma altre modalità contengono il supporto per il markup usato dai browser nel passato. L’obbiettivo è la retro-compatibilità con i vecchi contenuti. La versione strict corrente è la seguente : http://www.w3.org/TR/html4/strict.dtd
DOM
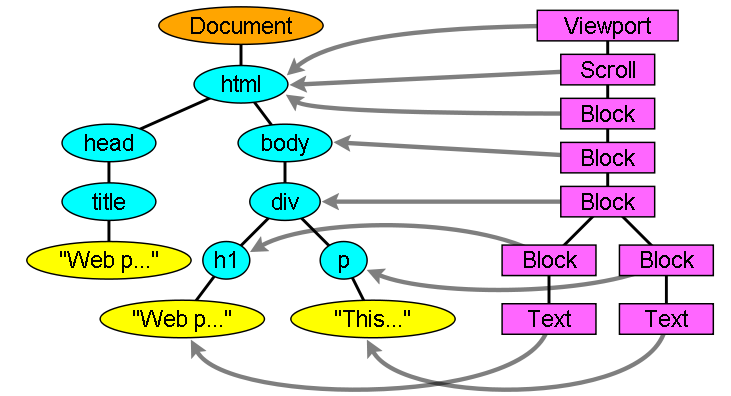
Il risultato finale dell’analisi del parser (il “parse tree“) è un albero di elementi del DOM e nodi di attributi. DOM è un acronimo che sta per Document Object Model. È la rappresentazione come oggetto del documento HTML e l’interfaccia di accesso agli elementi HTML al mondo esterno come il parser JavaScript. La radice dell’albero è l’oggetto “Document“. Il DOM ha una relazione che corrisponde quasi 1:1 con il codice. Ad esempio il seguente HTML :
|
1 2 3 4 5 6 7 8 |
<html> <body> <p> Hello World </p> <div> <img src="example.png"/></div> </body> </html> |
Sarebbe tradotto nel seguente albero DOM :
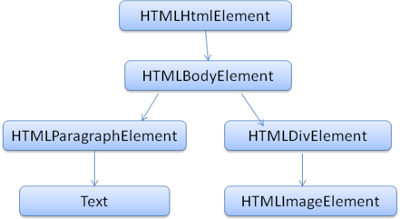
Come per l’HTML, il DOM è specificato dall’organizzazione del W3C. Consulta la pagina www.w3.org/DOM/DOMTR. È una specifica generica per la manipolazione dei documenti. Un modulo specifico descrive anche gli elementi HTML. Le definizione per l’HTML si trovano alla seguente pagina : http://www.w3.org/TR/2003/REC-DOM-Level-2-HTML-20030109/idl-definitions.html. Quando affermo che l’albero è composto da nodi del DOM, intendo che l’albero è costituito da elementi che implementano una delle interfacce del DOM. I browser usano implementazioni concrete che hanno ulteriori attributi utilizzati dal browser internamente.
L’algoritmo di parsing
Come abbiamo visto nelle precedenti sezioni, l’HTML non può essere analizzato usando il regolare processo top-down o bottom-up dei parser. Le ragioni sono le seguenti :
- La natura “clemente” del linguaggio.
- Il fatto che i browser hanno tradizionalmente un supporto per la tolleranza di errori riguardanti casi noti di HTML invalido.
- Il processo di analisi è rientrante. Per altri linguaggi, la sorgente non cambia durante la fase di analisi, ma per l’HTML, il codice dinamico (come elementi script inline contenenti chiamate document.write() ) può aggiungere nuovi frammenti, quindi il processo di analisi modifica il sorgente stesso.
Nell’impossibilità di utilizzare tecniche di parsing tradizionali, ciascun browser usa un proprio parser per analizzare l’HTML. L’algoritmo di analisi è descritto dettagliatamente nelle specifiche HTML5. L’algoritmo consiste di due fasi : frammentazione e costruzione dell’albero. La frammentazione è l’analisi lessicale, trasformando il codice sorgente in entrata in frammenti. Tra i frammenti HTML ci sono i tag iniziali, i tag finali, i nomi degli attributi ed i valori degli attributi. Il frammentatore riconosce i frammenti, li passa al costruttore dell’albero, e passa ai caratteri successivi per riconoscere i prossimi frammenti, e cosi via fino alla fine del codice.
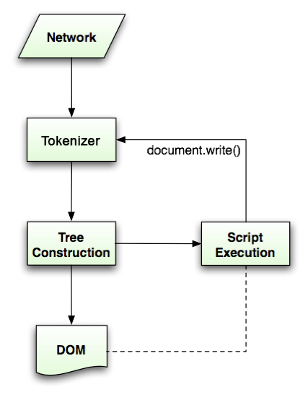
L’algoritmo di frammentazione
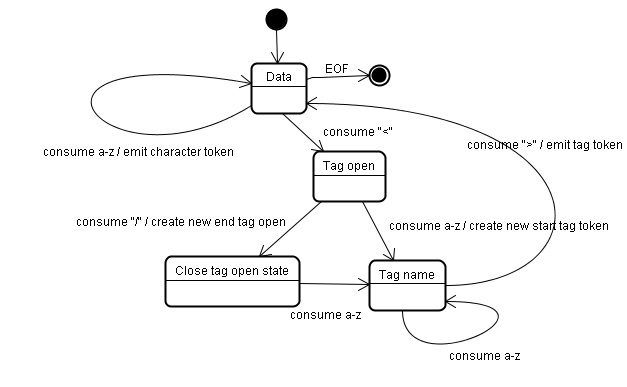
Il risultato dell’algoritmo è un frammento HTML. L’algoritmo è espresso come una macchina a stati finiti. Ogni stato riceve uno o più caratteri del flusso di codice ed aggiorna lo stato successivo in base a quei caratteri. La decisione è influenzata dallo stato corrente di frammentazione e dallo stato della costruzione dell’albero. Ciò significa che uno stesso carattere analizzato restituirà un risultato diverso, corretto per lo stato successivo, in dipendenza dallo stato corrente. L’algoritmo è troppo complesso per essere spiegato completamente, quindi vediamo un esempio semplice per comprenderne il principio : Esempio base, frammentazione del seguente HTML :
|
1 2 3 4 5 |
<html> <body> Hello world </body> </html> |
Lo stato iniziale è “Data state”. Quando il carattere “ <” viene incontrato, lo stato cambia in “Tag open state“. La ricezione di una serie di caratteri compresi tra a-z causa la creazione di uno “Start tag token”, lo stato viene cambiato in “Tag name state“. Si rimane in questo stato finché non viene incontrato il carattere “ >”. Ogni carattere viene appeso al nome del nuovo frammento. Nel nostro caso il frammento creato è un frammento html. Quando il carattere “ >” viene raggiunto, il frammento attuale viene emesso e lo stato ritorna in “Data state“. Il tag <body> sarà trattato con gli stessi passi. A questo punto sono stati emessi i tag html e body. Ora siamo di nuovo nello stato “Data state“. Arrivati al primo carattere H della parola Hello world avverrà l’emissione di un frammento di carattere, l’operazione si ripete finchè non viene raggiunto il carattere “ <” del tag </body>. Verrà emesso un frammento di carattere per ogni lettera che compone la stringa Hello world. Adesso siamo tornati allo stato “Tag open state“. La ricezione del prossimo carattere “ /” causerà la creazione di un frammento di fine tag per poi spostarsi allo stato “Tag name state“. Di nuovo si resta in questo stato fino al raggiungimento del carattere “ >”. Poi il nuovo frammento di tag verrà emesso per tornare allo stato “Data state”. I caratteri </html> saranno trattati allo stesso modo.
Algoritmo di costruzione dell’alberatura
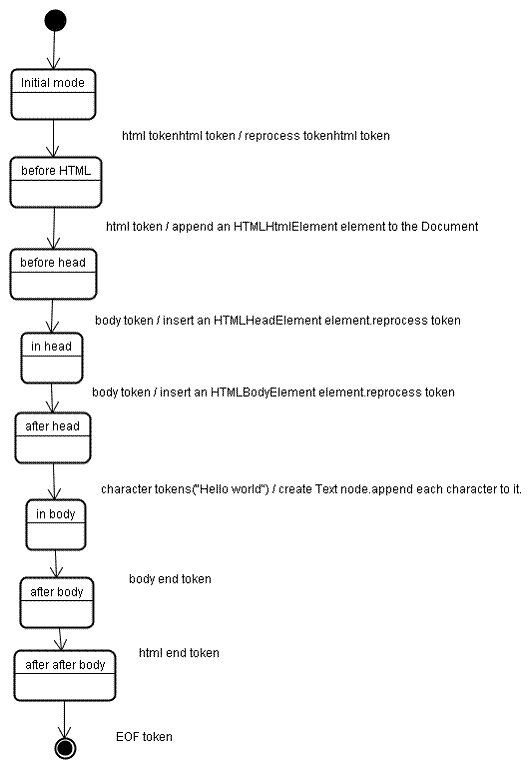
Quando l’analisi viene generata anche il DOM viene creato. Durante la fase di costruzione dell’alberatura il DOM, con l’oggetto Document come radice, verrà modificato e gli elementi verrano progressivamente aggiunti. Ogni nodo emesso dal frammentatore sarà processato dal costruttore dell’alberatura. Per ogni frammento le specifiche definiscono quale elemento del DOM è correlato e viene inserito per quel frammento. L’elemento è quindi aggiunto all’alberatura del DOM e anche alla lista degli elementi aperti. Questa lista viene usata per correggere eventuali errori di annidamento causati da tag non chiusi correttamente. L’algoritmo è descritto anche come una macchina a stati, gli stati sono chiamati “modalità di inserimento”. Vediamo il processo di costruzione per il seguente codice di esempio :
|
1 2 3 4 5 |
<html> <body> Hello world </body> </html> |
Gli elementi di base per la costruzione dell’albero provengono dalla sequenza di frammenti prodotti dalla fase di frammentazione. La prima modalità è “initial mode“. La ricezione del frammento “ html” causerà lo spostamento verso la modalità “before html” ed il riprocessamento del frammento in tale modalità. Questo causerà la creazione dell’elemento HTMLhtmlElement, che sarà appessò alla radice dell’oggetto Document. Lo stato cambia quindi in “before head“. Poi viene ricevuto il frammento “ body”. Un elemento HTMLHeadElement verrà creato inplicitamente anche se non è stato emanato il frammento e sarà aggiunto all’albero. Ora lo stato si sposta verso la modalità “in head” e successivamente “after head“. Il frammento body viene quindi riprocessato, viene creato l’elemento HTMLBodyElement e la modalità passa a “in body“. I frammenti di carattere della stringa Hello world vengono ricevuti. Il primo causerà la creazione e l’inserimento di un nodo Text e gli altri caratteri verrano appesi a quel nodo. La ricezione del frammento di chiusura del body causerà il cambiamento della modalità in “after body“. Viene quindi ricevuto il tag di chiusura html che cambia la modalità in “after after body“. La ricezione del frammento di fine file terminerà l’operazione di analisi del parser.
Azioni al termine dell’analisi
A questo punto il browser marca il documento come interattivo ed inzia ad analizzare gli script che sono in modalità “differita” : quelli che devono essere eseguiti dopo l’analisi del documento. Lo stato del documento passerà quindi a completo ed un evento load viene emesso. Puoi consultare l’algoritmo completo per la frammentazione e costruzione dell’alberatura nelle specifiche HTML5.
La tolleranza agli errori del browser
Non si ottiene mai l’errore “Invalid Syntax” con una pagina HTML. I browser aggiustano ogni contenuto invalido in tempo reale. Prendiamo questo HTML per esempio :
|
1 2 3 4 5 6 7 8 9 |
<html> <mytag> </mytag> <div> <p> </div> Really lousy HTML </p> </html> |
Ci sono almeno un milione di regole violate tutte insieme (“mytag” non è un tag standard, errato annidamento di “p” e “div” e molto altro) ma il browser mostra ugualmente il documento in maniera corretta e non si lamenta. Una gran parte del codice del parser consiste nell’aggiustamento degli errori dell’autore dell’HTML. La gestione degli errori è molto consistente nei browser, ma sorprendentemente non è mai stata parte delle specifiche HTML. Come per i bookmarks ed i tasti di navigazione indietro/avanti è qualcosa che si è andata evolvendo nei browser nel corso degli anni. Ci sono costrutti HTML invalidi ben conosciuti ripetuti su diversi siti, ed i browser cercano di aggiustarli in modo coerente tra di loro. Le specifiche HTML5 definiscono alcuni di questi requisiti. (WebKit li riassume bene nel commento che si trova all’inizio della funzione della classe del parser HTML.)
Il parser analizza elementi frammentati nel documento, costruendo l’alberatura del documento. Se il documento è ben formato, l’operazione è diretta. Sfortunatamente, dobbiamo gestire diversi documenti HTML che non sono ben formati, quindi il parser deve essere tollerante verso gli errori. Dobbiamo preoccuparci almeno delle seguenti condizioni di errore:
-
L’elemento che viene aggiunto è esplicitamente proibito all’interno di un tag che lo contiene. In questo caso dovremmo chiudere tutti i tag fino a quello che proibisce l’elemento, ed aggiungerlo successivamente.
-
Non è consentito inserire l’elemento direttamente. È possibile che la persona che ha scritto il documento abbia dimenticato alcuni tag nel mezzo (o che il tag nel mezzo è opzionale). Questo può succedere con i seguenti tag : HTML HEAD BODY TBODY TR TD LI (ne ho dimenticato qualcuno?).
-
Vogliamo aggiungere un elemento block dentro un elemento inline. Chiudere tutti gli elementi inline fino al prossimo elemento block.
-
Se questo non aiuta, chiudere gli elementi fino a che non è consentito inserire l’elemento – oppure ignora il tag.
Vediamo alcuni esempi di tolleranza agli errori di WebKit : </br> invece di <br> Alcuni siti usano </br> invece di <br>. Per rimanere compatibile con IE e Firefox, WebKit tratta l’elemento come un <br>. Il codice :
|
1 2 3 4 |
if (t->isCloseTag(brTag) && m_document->inCompatMode()) { reportError(MalformedBRError); t->beginTag = true; } |
Notare che la gestione dell’errore è interna, non verrà presentata all’utente. Una tabella vagante Una tabella vagante è una tabella dentro un’altra tabella, ma non all’interno di una table-cell. Ad esempio :
|
1 2 3 4 5 6 |
<table> <table> <tr><td>inner table</td></tr> </table> <tr><td>outer table</td></tr> </table> |
WebKit cambierà la gerarchia in due tabelle sorelle :
|
1 2 3 4 5 6 |
<table> <tr><td>outer table</td></tr> </table> <table> <tr><td>inner table</td></tr> </table> |
Il codice :
|
1 2 |
if (m_inStrayTableContent && localName == tableTag) popBlock(tableTag); |
WebKit usa un odine per i contenuti dell’elemento corrente: porterà all’esterno la tabella interna, in modo che le due diventino sorelle. Elementi form annidati Nel caso in cui lo sviluppatore inserisca un form dentro un altro form, il secondo form verrà ignorato. Il codice:
|
1 2 3 |
if (!m_currentFormElement) { m_currentFormElement = new HTMLFormElement(formTag, m_document); } |
Gerarchia di tag troppo profonda Il commento parla da solo :
www.liceo.edu.mx è un esempio di sito che riesce ad ottenere un livello di annidamento di circa 1500 tags, tutti da una serie di <b>. Consentiremo solo un massimo di 20 annidamenti dello stesso tipo prima di ignorarli tutti completamente.
|
1 2 3 4 5 6 7 8 9 |
bool HTMLParser::allowNestedRedundantTag(const AtomicString& tagName) { unsigned i = 0; for (HTMLStackElem* curr = m_blockStack; i < cMaxRedundantTagDepth && curr && curr->tagName == tagName; curr = curr->next, i++) { } return i != cMaxRedundantTagDepth; } |
Tag di chiusura html o body malposti Nuovamente- il commento parla da solo.
Supporto per HTML veramente scassato. Non chiudiamo mai il tag body, dato che alcune stupide pagine web lo chiudono prima della reale fine del documento. Affidiamoci alla chiamata end() per chiudere tutto.
|
1 2 |
if (t->tagName == htmlTag || t->tagName == bodyTag ) return; |
Quindi cari autori fate attenzione, a meno che non vogliate apparire come snippet di esempio della tolleranza agli errori di WebKit, scrivete del codice HTML ben formato.
Parser CSS
Ricordi i concetti relativi ai parser dell’introduzione? Ebbene, diversamente dall’HTML, il CSS è una grammatica libera dal contesto e può essere analizzata usando le tipologie di parser descritti nell’introduzione. Infatti le specifiche CSS definiscono anche la grammattica lessicale e sintattica del linguaggio. Vediamo alcuni esempi: La grammatica lessicale (vocabolario) è definita tramite espressioni regolari per ogni frammento :
|
1 2 3 4 5 6 7 |
comment /*[^*]**+([^/*][^*]**+)*/ num [0-9]+|[0-9]*"."[0-9]+ nonascii [200-377] nmstart [_a-z]|{nonascii}|{escape} nmchar [_a-z0-9-]|{nonascii}|{escape} name {nmchar}+ ident {nmstart}{nmchar}* |
“ident” è un’abbreviazione di identifier, come il nome di una classe, “name” è l’identificatore di un elemento (che viene referenziato con il simbolo “#”) La sintassi della grammatica è descritta in linguaggio BNF.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
ruleset : selector [ ',' S* selector ]* '{' S* declaration [ ';' S* declaration ]* '}' S* ; selector : simple_selector [ combinator selector | S+ [ combinator? selector ]? ]? ; simple_selector : element_name [ HASH | class | attrib | pseudo ]* | [ HASH | class | attrib | pseudo ]+ ; class : '.' IDENT ; element_name : IDENT | '*' ; attrib : '[' S* IDENT S* [ [ '=' | INCLUDES | DASHMATCH ] S* [ IDENT | STRING ] S* ] ']' ; pseudo : ':' [ IDENT | FUNCTION S* [IDENT S*] ')' ] ; |
Esempio, un insieme di regole CSS ha questa struttura :
|
1 2 3 4 |
div.error, a.error { color:red; font-weight:bold; } |
div.error e a.error sono selettori. La parte all’interno delle parentesi graffe contiene delle regole che sono applicate da questo insieme. Questa struttura è definita formalmente in questo modo :
|
1 2 3 4 |
ruleset : selector [ ',' S* selector ]* '{' S* declaration [ ';' S* declaration ]* '}' S* ; |
Questo significa che un insieme di regole è costituito da uno o più selettori separati da una virgola e spazi ( S sta per spazio vuoto). Un insieme di regole contiene delle parentesi graffe e al suo interno una o più dichiarazioni separate da punto e virgola
Parser CSS di WebKit
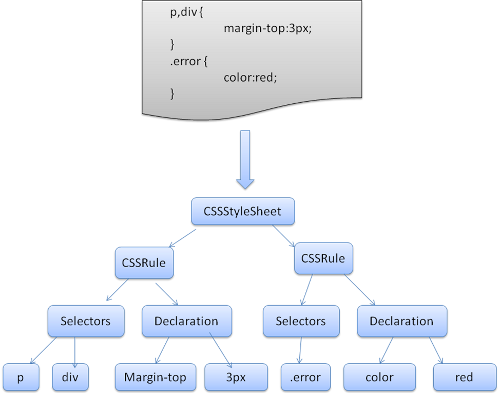
WebKit utilizza i generatori di parser Flex e Bison per generare automaticamente i propri parser dai file della grammatica CSS. Come ricorderai dall’introduzione, Bison crea un parser bottom-up shift reduce. Firefox usa un parser top-down scritto a mano. In entrambi i casi ogni file CSS viene analizzato e tradotto in un oggetto StyleSheet. Ogni oggetto contiene regole CSS. Gli oggetti CSS rule contengono oggetti selector e declaration ed altri oggetti corrispondenti alla grammatica CSS.
L’ordine di processamento degli script e dei fogli di stile
Scripts
Il modello del web è sincrono. Gli sviluppatori si aspettano che gli script vegano analizzati ed eseguiti immediatamente quando il parser raggiunge il tag <script>. L’analisi del documento si ferma finchè lo script non è stato eseguito. Se lo script è esterno allora la risorsa deve prima essere recuperata dalla rete, anche questo passaggio avviene in modo sincrono, e l’analisi si ferma finchè la risorsa non è stata scaricata. Questo è stato il modello per diversi anni ed è anche definito nelle specifiche di HTML4 ed HTML5. Gli sviluppatori possono aggiungere l’attributo “ defer” allo script, nel qual caso non fermerà l’analisi del documento e verrà eseguito al termine dell’analisi. L’HTML5 aggiunge un opzione per marcare lo script come asincrono in modo che possa essere analizzato ed eseguito in un processo separato.
Analisi speculativa
Sia WebKit che Gecko compiono questa ottimizzazione. Mentre eseguono gli script, un altro processo analizza il resto del documento per scoprire quali altre risorse devono essere recuperate dalla rete e le scarica. In questo modo le risorse possono essere caricate con connessioni parallele e la velocità generale migliora. Nota : il parser speculativo analizza solo i riferimenti alle risorse esterne quali script, fogli di stile ed immagini: non modifica l’alberatura del DOM, compito che resta delegato al parser principale.
Fogli di stile
I fogli di stile usano un modello diverso. Concettualmente sembrerebbe che siccome gli stili non alterano l’albero del DOM, non ci sia bisogno di aspettare che siano stati caricati e quindi di fermare l’analisi del documento per aspettare. Tuttavia si verificano dei problemi quando gli script richiedono informazioni di stile durante la fase di analisi del documento. Se lo stile non è stato ancora scaricato ed analizzato, lo script avrà una risposta sbagliata e apparentemente questo causa diversi problemi. Può sembrare un caso limite ma in realtà è molto comune. Firefox blocca tutti gli script se ci sono dei fogli di stile che devono essere ancora scaricati e analizzati. WebKit blocca gli script solo quando cercano di accedere determinate proprietà di stile che potrebbero dipendere da fogli di stile non ancora scaricati.
Costruzione dell’albero di render
Mentre l’albero del DOM viene costruito, il browser costruisce un altro albero, ovvero l’albero di render. Questo albero è composto da elementi visuali disposti nell’ordine in cui verranno mostrati sullo schermo. È la rappresentazione visuale del documento. Lo scopo di questo albero è di consentire la pittura (painting) dei contenuti nell’ordine corretto. Firefox chiama gli elementi dell’albero di render “frames“. WebKit usa i termini renderer o anche render object. Un renderer sa come disporsi e pitturare se stesso e i propri figli sulla schermo. La classe di WebKit RenderObject, che è la classe base dei renderer, ha la seguente definizione :
|
1 2 3 4 5 6 7 8 |
class RenderObject{ virtual void layout(); virtual void paint(PaintInfo); virtual void rect repaintRect(); Node* node; //the DOM node RenderStyle* style; // the computed style RenderLayer* containgLayer; //the containing z-index layer } |
Ogni renderer rappresenta un’area rettangolare che solitamente corrisponde al blocco CSS del nodo, come descritto nelle specifiche CSS2. Include informazioni geometriche quali larghezza, altezza e posizione. La tipologia del blocco è influenzata dal valore della proprietà “ display” dell’attributo di stile rilevante per il nodo (consulta la sezione sulla computazione degli stili). Ecco il modo in cui il codice di WebKit decide quale tipo di renderer debba essere creato per un nodo del DOM, sulla base dell’attributo “ display” :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
RenderObject* RenderObject::createObject(Node* node, RenderStyle* style) { Document* doc = node->document(); RenderArena* arena = doc->renderArena(); ... RenderObject* o = 0; switch (style->display()) { case NONE: break; case INLINE: o = new (arena) RenderInline(node); break; case BLOCK: o = new (arena) RenderBlock(node); break; case INLINE_BLOCK: o = new (arena) RenderBlock(node); break; case LIST_ITEM: o = new (arena) RenderListItem(node); break; ... } return o; } |
Anche la tipologia dell’elemento viene considerata : per esempio i controlli dei form e delle tabelle hanno oggetti speciali. In WebKit se un elemento vuole creare un renderer speciale, sovrascriverà il metodo createRenderer(). I renderer puntano agli oggetti di stile che contengono informazioni non geometriche.
La relazione tra Albero di Render e Albero del DOM
I renderer corrispondono ad elementi del DOM, ma la relazione non è uno a uno. Gli elementi non-visuali del DOM non vengono inseriti nell’alberatura di render. Un esempio è l’elemento “ head”. Inoltre gli elementi a cui è stato attribuito il valore display a “ none” non appariranno nell’alberatura (mentre gli elementi con visibility : hidden appariranno comunque nell’alberatura). Ci sono elementi del DOM che corrispondono a diversi oggetti visuali. Sono di solito elementi dotati di una struttura complessa che non può essere descritta con un singolo rettangolo. Per esempio, l’elemento “ select” ha associati tre renderer : uno per l’area in cui viene mostrato, un altro per la lista di elementi in drop down ed un altro ancora per il pulsante. Inoltre quando il testo deve apparire su più righe perché la larghezza non è sufficiente a contenerlo su una riga singola, le nuove righe verranno inserite come renderer aggiuntivi. Un altro esempio di renderer multipli si ha con l’HTML rotto. Stando alle specifiche CSS un elemento inline deve contenere o solo elementi di tipo block o solo elementi di tipo inline. Nel caso di contenuti misti, dei blocchi renderer anonimi verranno aggiunti per racchiudere gli elementi inline. Alcuni renderer corrispondono a nodi del DOM ma non nello stesso punto dell’alberatura. Gli elementi flottanti o con posizionamento assoluto sono esterni al flusso, posizionati in un punto diverso dell’alberatura, e mappati all’elemento reale. Un elemento segnaposto viene inserito per indicare dove si sarebbero dovuti trovare.
Il flusso di costruzione dell’albero
In Firefox la presentazione è registrata come un listener per gli aggiornamenti del DOM. La presentazione delega la creazione dei frame al costruttore FrameConstructor che si occupa di risolvere gli stili (consulta la computazione degli stili) e crea i frame. In WebKit il processo di risoluzione degli stili e creazione di un renderer è chiamato “attachment“. Ogni nodo del DOM ha un metodo “attach“. L’operazione è sincrona, l’inserimento nel DOM di un nodo chiama il metodo “attach“. Il processamento dei tag html e body risulta nella costruzione della radice dell’albero di render. L’oggetto di render posto a radice corrisponde a ciò che le specifiche CSS chiamano “blocco contenitore” : il blocco superiore che contiene tutti gli altri blocchi. Le sue dimensioni corrispondono al viewport, cioè le dimensioni dell’area di visualizzazione nella finestra del browser. FIrefox lo chiama ViewPortFrame e WebKit lo chiama RenderView. Questo è l’oggetto di render a cui punta il documento. Il resto dell’albero è costruito tramite inserimento di nodi del DOM. Consulta le specifiche CSS sul modello di processamento.
Computazione degli stili
La costruzione dell’albero di render richiede il calcolo delle proprietà visuali di ciascun renderer, risultato che si ottiene calcolando le proprietà di stile di ogni elemento. Gli stili includono fogli di stile di varia origine, stili inline e proprietà visuali nell’HTML (come la proprietà “ bgcolor”). Il tutto viene tradotto per corrispondere a proprietà di stile CSS. L’origine dei fogli di stile può essere il set predefinito del browser, i fogli definiti dall’autore e dall’utente (il browser permette agli utenti di definire dei propri stili. In Firefox, ad esempio, si può fare inserendo un foglio di stile nella cartella “Firefox Profile”). La computazione degli stili solleva diverse problematiche :
- L’insieme degli stili è un costrutto estremamente grande, contenente numerose proprietà di stile, questo può causare problemi di memoria.
- Trovare la corrispondenza tra le regole per ogni elemento può causare problemi di prestazioni se non ottimizzata. Esaminare l’intera lista di regole per ogni elemento per trovare le corrispondenze è un’attività onerosa. I selettori possono avere strutture complesse che possono portare l’inizio dell’analisi a procedere su una strada promettente che si rileva poi errata portando quindi a provare altre strade.Per esempio, questo selettore composto :
123div div div div{...}
Significa che la regola si applica ai <div> che sono discendenti di tre div. Supponiamo di voler controllare che la regola sia valida per un determinato elemento. Scegliamo una determinata strada nell’alberatura per controllare. Potrebbe essere necessario dover risalire nel DOM solo per constatare che ci sono solo due div superiori e la regola non si applica. Quindi bisogna cercare un’altra strada nell’albero. - L’applicazione delle regole richiede una cascata complessa di regole che definiscono la gerarchia delle regole stesse.
Vediamo come i browser affrontano questi problemi.
Condivisione dei dati degli stili
I nodi di WebKit referenziano gli oggetti di stile ( RenderStyle). Questi oggetti possono essere condivisi tra i nodi in base ad alcune condizioni. I nodi devono essere parenti o cugini e :
- Gli elementi devono avere lo stesso mouse-state (quindi uno dei due non può essere in :hover mentre l’altro non lo è).
- Nessuno dei due elementi deve avere un ID
- I nomi dei tag devono coincidere
- Gli attributi della classe devono coincidere
- Il set di attributi mappati deve essere identico
- Lo stato :link deve coincidere
- Lo stato :focus deve coincidere
- Nessuno dei due elementi deve essere affetto da un selettore di attributi (attribute selector), dove affetto è definito come avere qualunque selettore che usa una selezione via attributo in qualunque posizione del selettore.
- Non ci devono essere stili inline sugli elementi
- Non ci devono essere selettori di parentela (sibiling selector). WebCore emette un segnale globale quando selettori parenti vengono trovati e disabilita la condivisione degli stili per l’intero documento quando sono presenti. Questo include il selettore + e pseudo-selettori come :first-child e :last-child.
L’alberatura di regole di Firefox
Firefox ha due alberi extra per facilitare la computazione degli stili : l’albero di regole (rule tree) e l’albero dei contesti degli stili (style context tree). Anche WebKit ha gli oggetti di stile ma non sono memorizzati in un’alberatura come quella del contesto degli stili, solo i nodi del DOM puntano agli stili opportuni.
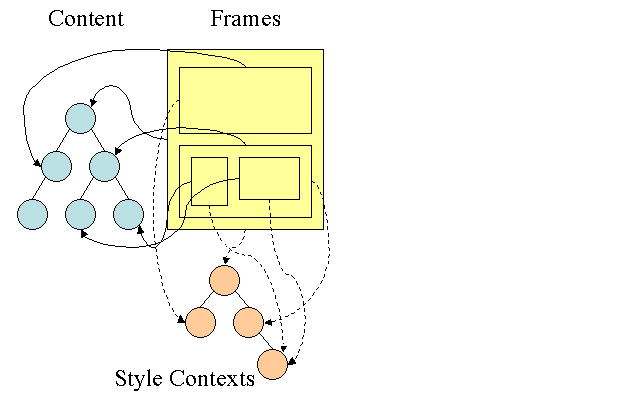
I contesti degli stili contengono i valori finali. I valori sono calcolati applicando tutte le regole corrispondenti nell’ordine corretto e performando delle manipolazioni che li trasformano da valori logici a valori concreti. Per esempio, se il valore logico è una percentuale dello schermo verrà calcolata e trasformata in un’unità assoluta. L’idea dell’albero di regole è molto intelligente. Abilita la condivisione di questi valori tra nodi evitando di doverli ricalcolare di nuovo. Questo permette anche di risparmiare memoria. Tutte le regole corrisposte vengono memorizzate in un albero. Il nodo finale in un percorso ha priorità maggiore. L’albero contiene tutti i percorsi per le regole corrispondenti che sono stati trovati. La memorizzazione delle regole avviene in modalità lazy. L’albero non viene calcolato all’inizio di ogni nodo, ma ogni qualvolta che gli stili di un nodo necessitano di essere calcolati allora anche i percorsi calcolati sono aggiunti all’albero. L’idea è di vedere i percorsi dell’albero come un lessico. Consideriamo di aver già computato il seguente albero di regole : 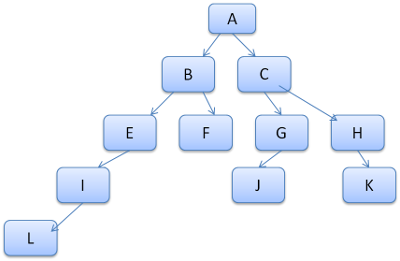 Supponiamo di dovere far corrispondere le regole per un altro elemento nell’albero dei contenuti, e scopriamo che le regole che corrispondono sono (nell’ordine corretto) B-E-I. Abbiamo già questo percorso nell’albero perché abbiamo già computato A-B-E-I-L. Quindi avremo meno lavoro da svolgere. Vediamo come l’albero ci risparmia il lavoro.
Supponiamo di dovere far corrispondere le regole per un altro elemento nell’albero dei contenuti, e scopriamo che le regole che corrispondono sono (nell’ordine corretto) B-E-I. Abbiamo già questo percorso nell’albero perché abbiamo già computato A-B-E-I-L. Quindi avremo meno lavoro da svolgere. Vediamo come l’albero ci risparmia il lavoro.
Divisione in struct
I contesti degli stili sono suddivisi in struct. Questi struct contengono informazioni di stile di una determinata categoria come bordi o colore. Tutte le proprietà in uno struct sono o ereditate o non ereditate. Le proprietà ereditate sono quelle che se non definite sull’elemento, sono ereditate dal genitore. Proprietà non ereditate (chiamate proprietà “reset“) usano valori predefiniti se non definite. L’albero ci aiuta racchiudendo interi struct (contenenti i valori finali calcolati). L’idea è che se l’ultimo nodo non ha fornito una definizione per uno struct, uno struct cachato in un nodo superiore può essere usato.
Computazione del contesto di stile usando l’albero di regole
Durante la computazione del contesto di stile per un certo elemento, prima calcoliamo un percorso nell’albero delle regole o ne usiamo uno esistente. Iniziamo allora ad applicare le regole nel percorso per riempire lo struct nel nostro nuovo contesto di stile. Iniziamo dal nodo finale del percorso, quello con la precedenza maggiore (solitamente il selettore più specifico) e si ripercorre l’albero verso l’alto finché lo struct è completo. Se non si trova nessuna specifica per lo struct in quel nodo di regole, allora possiamo ampiamente ottimizzare, si risale nell’albero fino a trovare un nodo che lo specifica e si punta a quello, questa è l’ottimizzazione migliore, l’intero struct è condiviso. Così si risparmia il calcolo dei valori finali e memoria. Se si trovano definizioni parziali si risale nell’albero finché lo struct non è completo. Se non abbiamo trovato nessuna definizione per il nostro struct allora, nel caso in cui lo struct sia di tipo ereditato, puntiamo allo struct del genitore nell albero del contesto. In questo caso siamo riusciti a far condividere gli struct. Se è uno struct reset allora verranno usati i valori predefiniti. Se il nodo più specifico aggiunge dei valori allora andranno fatti ulteriori calcoli per trasformarli in valori reali. Poi vengono salvati in cache i risultati nel nodo dell’albero così che possa essere usato dai suoi figli. Nel caso un elemento abbia un parente o un fratello che punta allo stesso nodo dell’albero allora l’intero contesto di stile può essere condiviso tra loro. Vediamo un esempio, supponiamo di avere questo HTML
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<html> <body> <div class="err" id="div1"> <p> this is a <span class="big"> big error </span> this is also a <span class="big"> very big error</span> error </p> </div> <div class="err" id="div2">another error</div> </body> </html> |
E le seguenti regole :
|
1 2 3 4 5 6 |
div {margin:5px;color:black} .err {color:red} .big {margin-top:3px} div span {margin-bottom:4px} #div1 {color:blue} #div2 {color:green} |
Per semplificare le cose supponiamo di aver bisogno di riempire solo due struct : lo struct del colore e lo struct dei margini. Il primo contiene un solo membro, il valore del colore, il secondo contiene quattro membri corrispondenti ai quattro lati. L’albero risultante avrà un aspetto simile (i nodi sono marcati con il nome del nodo : il numero della regola a cui puntano) :
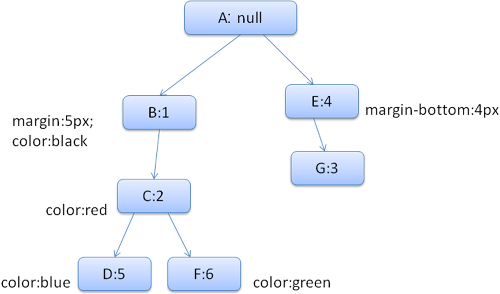
L’albero dei contesti avrà questa struttura (il nome del nodo è la regola a cui punta) :
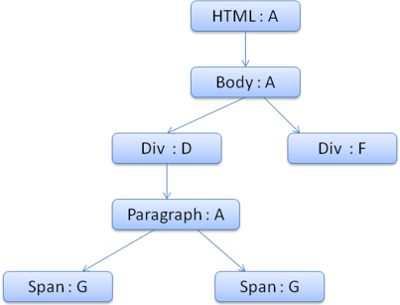
Supponiamo di analizzare l’HTML ed arrivare al secondo tag <div>. Dobbiamo creare un contesto di stile per questo nodo ed inserirvi i suoi struct. Faremo corrispondere le regole e scopriremo che quelle che combaciano per il <div> sono la 1, 2 e 6. Ciò significa che c’è già un percorso esistente nell’albero che il nostro elemento può usare e ci serve solo aggiungerci un altro nodo per la regola 6 (nodo F dell’albero di regole). Creeremo un contesto di stile e ci inseriremo l’albero di contesto. Il nuovo contesto di stile punterà al nodo F dell’albero di regole. Dobbiamo ora completare gli struct degli stili. Inizieremo popolando lo struct dei margini. Dato che l’ultimo nodo delle regole (F) non aggiunge margini allo struct, possiamo risalire nell’albero finché non troviamo uno struct cachato che è stato calcolato durante l’inserimento di un nodo precedente ed usiamo quello. Lo troveremo nel nodo B, che è il nodo più alto che ha definito delle regole per i margini. Abbiamo una definizione per lo struct del colore, quindi non possiamo usare uno struct già cachato. Siccome il colore ha un solo attributo non serve risalire nell’albero per completare altri attributi. Calcoleremo il valore finale (convertendo le stringe ad RGB etc) e metteremo in cache lo struct calcolato su questo nodo. Il lavoro sul secondo <span> è anche più semplice. Faremo corrispondere le regole per arrivare alla conclusione che punta alla regola G, come lo span precedente. Dato che abbiamo due parenti che puntano allo stesso nodo, possiamo condividere l’intero contesto di stile e puntare semplicemente al contesto dello span precedente. Per gli struct che contengono regole che sono ereditate dai genitori, la memorizzazione in cache avviene nell’albero di contesto (la proprietà colore in realtà viene ereditata, ma Firefox la tratta come reset e la memorizza nell’albero delle regole). Ad esempio se aggiungiamo delle regole per il font in un paragrafo :
|
1 |
p {font-family: Verdana; font size: 10px; font-weight: bold} |
Allora l’elemento paragrafo, che è figlio del div nell’albero di contesto, potrebbe avere in condivisione lo stesso struct per il font come il padre. Questo se nessuna regola di font viene specificata per il paragrafo. in WebKit, dove non esiste un albero di regole, le dichiarazioni corrispondenti sono ripercorse quattro volte. Prima vengono applicate le proprietà non-importanti ad alta priorità (proprietà che dovrebbero essere applicate per prime perché altre dipendono da esse, come per display), poi quelle ad alta priorità marcate !important. Ciò significa che proprietà che appaiono molteplici volte verranno risolte in base all’ordine corretto della cascata. L’ultimo vince. Per riassumere : la condivisione dell’oggetto di stile (interamente o solo alcuni struct all’interno) risolve i problemi 1 e 3. L’albero di regole di Firefox inoltre aiuta ad applicare le proprietà nell’ordine giusto.
Manipolazione delle regole per una corrispondenza semplice
Le regole di stile possono provenire da diverse sorgenti :
- Regole CSS, sia esterne che incorporate nell’html come tag style.
1p {font-family: Verdana; font size: 10px; font-weight: bold} - Attributi di stile inline.
1<p style="color: blue"></p> - Attributi HTML visuali (che sono mappati a delle regole di stile)
1<p bgcolor="blue"></p>
Gli ultimi due vengono corrisposti facilmente all’elemento dato che detiene gli attributi di stile e gli attributi HTML possono essere mappati usando l’elemento come chiave. Come constatato precedentemente per il problema 2, la corresponsione delle regole CSS può essere difficoltosa. Per risolvere la difficoltà, le regole vengono manipolate per consentire un accesso più semplice. Dopo aver analizzato il foglio di stile, le regole vengono aggiunte ad una o più hash-map in base al selettore. Ci sono mappe di ID, di classi, di nomi di tag ed una mappa generale per qualunque altra cosa non rientri in queste categorie. Se il selettore è un ID sarà aggiunto alla mappa degli ID, se è una classe viene aggiunto alla mappa delle classi etc. Questa manipolazione semplifica molto la corresponsione delle regole. Non serve più controllare ogni dichiarazione : possiamo estrarre le regole rilevanti per un elemento dalle mappe. Questa ottimizzazione rimuove il 95% delle regole, cosi che non non vengano neppure considerate durante il processo di corresponsione (4.1). Vediamo per esempio le seguenti regole di stile :
|
1 2 3 |
p.error {color: red} #messageDiv {height: 50px} div {margin: 5px} |
la prima regola sarà inserita nella mappa delle classi, la seconda nella mappa degli ID e la terza nella mappa dei tag. Per il seguente frammento HTML :
|
1 2 |
<p class="error">an error occurred </p> <div id=" messageDiv">this is a message</div> |
Cercheremo di trovare regole per l’elemento <p>. La mappa delle classi conterrà una chiave “ error” sotto la quale viene trovata la regola per “ p.error”. L’elemento div avrà le sue regole nella mappa degli ID (la chiave è l’ID) e anche nella mappa dei tag. Quindi il lavoro rimasto da svolgere è scoprire quali delle regole estratte dalle chiavi corrisponde davvero. Per esempio se le regola del div fosse:
|
1 |
table div {margin: 5px} |
verrebbe comunque estratta dalla mappa dei tag, perché la chiave è il selettore che si trova all’estrema destra, ma non corrisponderebbe al nostro elemento div, che non ha una tabella tra i suoi antenati. Sia WebKit che FIrefox applicano questa manipolazione.
Applicazione delle regole nell’ordine di cascata corretto
L’oggetto di stile ha proprietà che corrispondono ad ogni attributo visuale (tutti gli attributi CSS ma più generici). Se la proprietà non è definita da nessuna delle regole corrispondenti, allora alcune proprietà possono essere ereditate dall’oggetto di stile dell’elemento padre. Altre proprietà hanno valori predefiniti. I problemi iniziano quando c’è più di una definizione, qui interviene l’ordine a cascata per risolvere il problema.
Ordine di cascata dei fogli di stile
Una dichiarazione per una proprietà di stile può apparire in diversi fogli, e diverse volte dentro lo stesso foglio. Ciò significa che l’ordine per applicare le regole è molto importante. Questo ordine è definito cascata (cascade). Stando alle specifiche CSS2, l’ordine della cascata è (dal più basso al più alto) :
- Dichiarazioni del browser
- Dichiarazioni normali dell’utente
- Dichiarazioni normali dell’autore
- Dichiarazioni importanti dell’autore
- Dichiarazioni importanti dell’utente
Le dichiarazioni del browser sono le meno importanti e l’utente può sovrascrivere l’autore solo se le dichiarazioni sono marcate come importanti. Dichiarazioni con lo stesso ordine verrano filtrate prima per specificità e poi per l’ordine in cui sono dichiarate. Gli attributi HTML visuali sono tradotti in dichiarazioni CSS corrispondenti, sono trattati come regole dell’autore a bassa priorità.
Specificità
La specificità dei selettori è descritta nelle specifiche CSS2 come segue :
- Conta 1 se la dichiarazione viene da un attributo “ style” invece che da una regola con un selettore, altrimenti 0 (= a)
- Conta il numero di attributi ID nel selettore (= b)
- Conta il numero di altri attributi e pseudo-classi nel selettore (= c)
- Conta il numero di nomi di elementi e pseudo-elementi nel selettore (= d)
Concatenando i quattro numeri a-b-c-d (in un sistema numerico a base larga) si ottiene la specificità. Il numero di base che va usato è definito dal numero più alto che si ottiene in una delle quattro categorie. Per esempio, se a=14 puoi usare la base esadecimale. Nel caso di un poco probabile a=17 avrai bisogno di una base numerica a 17 cifre. L’ultima situazione può verificarsi con un selettore di questo tipo : html body div div p … (17 tag nel selettore, poco probabile). Alcuni esempi :
|
1 2 3 4 5 6 7 8 9 10 |
* {} /* a=0 b=0 c=0 d=0 -> specificity = 0,0,0,0 */ li {} /* a=0 b=0 c=0 d=1 -> specificity = 0,0,0,1 */ li:first-line {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */ ul li {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */ ul ol+li {} /* a=0 b=0 c=0 d=3 -> specificity = 0,0,0,3 */ h1 + *[rel=up]{} /* a=0 b=0 c=1 d=1 -> specificity = 0,0,1,1 */ ul ol li.red {} /* a=0 b=0 c=1 d=3 -> specificity = 0,0,1,3 */ li.red.level {} /* a=0 b=0 c=2 d=1 -> specificity = 0,0,2,1 */ #x34y {} /* a=0 b=1 c=0 d=0 -> specificity = 0,1,0,0 */ style="" /* a=1 b=0 c=0 d=0 -> specificity = 1,0,0,0 */ |
Filtraggio delle regole
Dopo che le regole sono state corrisposte, sono filtrate in base alle regole di cascata. WebKit usa un ordinamento a bolle (bubble sort) per liste piccole e un ordinamento ad unione (merge sort) per quelle grandi. WebKit implementa l’ordinamento sovrascrivendo l’operatore > per le regole :
|
1 2 3 4 5 6 |
static bool operator >(CSSRuleData& r1, CSSRuleData& r2) { int spec1 = r1.selector()->specificity(); int spec2 = r2.selector()->specificity(); return (spec1 == spec2) : r1.position() > r2.position() : spec1 > spec2; } |
Processo graduale
WebKit usa un segnale che marca se tutti i fogli di stile di alto livello (inclusi gli @imports) sono stati caricati. Se gli stili non sono completamente caricati durante la fase di “attacching” vengono usati dei segnaposto e sono segnati sul documento, verrano ricalcolati quando i fogli di stile saranno caricati.
Disposizione
Quando il renderer viene creato ed aggiunto all’albero, non possiede posizione e dimensioni. Il calcolo di questi valori è chiamato layout o reflow. L’HTML usa un modello di disposizione basato sul flusso, ciò significa che nella maggior parte dei casi è possibile computare la geometria in un singolo passaggio. Gli elementi più a valle “nel flusso” tipicamente non influenzano la geometria degli elementi che si trovano a monte “nel flusso”, quindi il processo di disposizione può avanzare da sinistra a destra, da sopra a sotto per tutto il documento. Ci sono delle eccezioni : per esempio, le tabelle HTML possono richiedere più di un passaggio. Il sistema di coordinate è relativo al frame principale, vengono usate le coordinate Top e Left. Layout è un processo ricorsivo. Ha inizio dal renderer radice, che corrisponde all’elemento <html> del documentl HTML Il processo di Layout prosegue ricorsivamente per alcuni o tutti i frame della gerarchia, computando informazioni geometriche per ogni renderer che le richiede. La posizione del renderer radice è 0,0 e le sue dimensioni corrispondono a quelle del viewport, la parte visibile della finestra del browser. Tutti i renderer hanno un metodo layout o reflow, ogni renderer invoca il metodo layout dei suoi figli che ne hanno bisogno.
Sistema dei bit sporchi
Per evitare di dover rieseguire una ridisposizione completa in seguito ad ogni piccolo cambiamento, i browser usano un sistema di “bit sporchi” (dirty bit). Un renderer che subisce cambiamenti o viene aggiunto marca se stesso e i propri figli come “sporchi” : necessitano di layout. Ci sono due segnali : “sporco”, e “figli sporchi” che significa che anche se il renderer stesso potrebbe andare bene, ha almeno un figlio che ha bisogno di layout.
Layout globale e incrementale
Il processo di layout può essere scatenato sull’intero albero di render, e sarebbe un layout globale. Ciò può accadere in conseguenza di :
- Uno stile globale che influenza tutti i renderer viene modificato, come il cambiamento di un font-size.
- Quando la finestra viene ridimensionata.
Il layout può essere incrementale, solo i renderer sporchi saranno ricalcolati (questa operazione può danneggiare elementi già renderizzati richiedendo ulteriori operazioni di layout). Il layout incrementale è innescato (asincronamente) quando i renderer sono sporchi. Per esempio quando nuovi renderer vengono appesi all’albero di render dopo che dei contenuti nuovi arrivano dal network e vengono aggiunti all’albero del DOM.
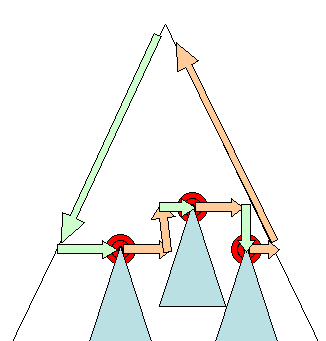
Layout asincrono e sincrono
Il layout incrementale viene svolto asincronamente. Firefox accoda i “comandi di reflow” per il layout incrementale ed uno schedulatore innesca l’esecuzione sequenziale di questi comandi. Anche WebKit ha un timer che esegue un layout incrementale, l’albero viene percorso ed i renderer “sporchi” vengono rielaborati. Gli script che richiedono informazioni di stile, come “ offsetHeight” possono innescare il processo di layout sincrono. Il layout globale viene generalmente innescato in modo sincrono. A volte il processo di layout viene innescato come callback in seguito ad un layout iniziale perchè alcuni attributi, come la posizione dello scroll, sono cambiati.
Ottimizzazioni
Quando un processo di layout viene innescato da un ridimensionamento o da un cambiamento della posizione del renderer (e non la dimensione), le dimensioni del renderer sono prese dalla cache e non vengono ricalcolate. In alcuni casi solo un sotto-albero viene modificato e il layout non inizia dalla radice. Questo può accadere nei casi in cui il cambiamento è locale e non influisce sugli elementi circostanti, come un testo inserito in un textfield (altrimenti ogni tasto premuto innescherebbe un processo di layout che parte dalla radice).
Il processo di layout
Il processo di layout segue generalmente questo comportamento :
- Il renderer genitore determina la propria larghezza
- Il genitore analizza i figli e :
- Piazza il renderer figlio (imposta X ed Y)
- Chiama il metodo layout del figlio se necessario – sono sporchi o siamo in modalità layout globale, o per qualche altra ragione – che calcola l’altezza del figlio.
- Il genitore usa le altezze sommate dei figli e le altezze dei margini e padding per impostare la propria altezza, la quale sarà usata dal renderer genitore dell’attuale renderer.
- Imposta il proprio dirty bit a false.
Firefox usa un oggetto “state” ( nsHTMLReflowState) come parametro del layout (in Gecko chiamato reflow). Tra le altre cose lo stato include la larghezza del genitore. Il risultato del layout di Firefox è un oggetto “metrica” ( nsHTMLReflowMetrics). Conterrà l’altezza calcolata del renderer.
Calcolo della larghezza
La larghezza del renderer è calcolata usando la larghezza del blocco contenitore, cioè la proprietà di stile “width” del renderer, includendo margini e bordi. Per esempio la larghezza del seguente <div> :
|
1 |
<div style="width: 30%"></div> |
Sarebbe calcolata da WebKit in questo modo (classe RenderBox metodo calcWidth) :
- La larghezza del contenitore equivale al valore più grande tra le
availableWidth dei contenitori e 0. La
availableWidth in questo caso equivale alla
contentWidth che viene calcolata come :
1clientWidth() - paddingLeft() - paddingRight()
clientWidth e clientHeight rappresentano l’interno di un oggetto escludendo bordi e scrollbar. - La larghezza degli elementi corrisponde all’attributo di stile “ width”. Verrà calcolato come valore assoluto computando la percentuale della larghezza del contenitore.
- I bordi e padding orizzontali vengono sommati.
Fin qui si trattava del calcolo della “larghezza preferita”. Ora verranno calcolate le larghezze massime e minime. Se la larghezza preferita è maggiore della larghezza massima, verrà usata la larghezza massima. Se è minore della larghezza minima (l’unità indivisibile più piccola) allora viene usata la larghezza minima. I valori vengono cachati nel caso serva eseguire un layout in cui la larghezza non cambia.
Line breaking
Quando un renderer coinvolto in un processo di layout decide di doversi spezzare, il renderer si ferma e propaga ai genitori del layout che deve essere spezzato. Il genitore crea dei renderer aggiuntivi e vi applica il layout.
Pittura
Nella fase di pittura (painting), l’albero di render viene ripercorso e il metodo paint() di ciascun renderer viene invocato per mostrare il contenuto sullo schermo. Il processo di pittura usa l’infrastruttura del componente UI.
Globale e incrementale
Come il processo layout, il painting può essere a sua volta globale – l’intero albero viene pitturato – o incrementale. Nella pittura incrementale, alcuni dei renderer cambiano in un modo che non influisce sull’intero albero. Il renderer modificato invalida il suo rettangolo sullo schermo. Questo porta il sistema operativo a vederlo come una “regione sporca” e genera un evento “paint“. Il sistema operativo esegue l’operazione in maniera intelligente ed unisce più regioni in una sola. In Chrome è più complicato perché il renderer si trova in un processo differente rispetto a quello principale. Chrome simula il comportamento del sistema operativo fino a un certo punto. La presentazione ascolta questi eventi e delega il messaggio alla radice di render. L’albero viene ripercorso finché non viene raggiunto il renderer specifico, il quale ripitturerà se stesso (e solitamente anche i propri figli).
L’ordine di Pittura
Il CSS2 definisce l’ordine del processo di pittura. In realtà è l’ordine in cui gli elementi sono memorizzato nel contesto di catasto (stacking context). Questo ordine influisce sulla fase di pittura poiché gli elementi sono pitturati dal più retrocesso al più frontale. L’ordine di catasto del blocco di un renderer è :
- colore di sfondo
- immagine di sfondo
- bordi
- figli
- esterno (outline)
Lista di visualizzazione di Firefox
Firefox percorre l’albero di render e costruisce una lista di visualizzazione (display list) per i rettangoli pitturati. Contiene i renderer rilevanti per i rettangoli, nel giusto ordine di pittura (sfondi dei renderer, poi i bordi etc). In questo modo l’albero deve essere percorso una sola volta per essere ripitturato invece di diverse volte, per pitturare tutti gli sfondi, poi le immagini, poi i bordi etc. Firefox ottimizza il processo non aggiungendo elementi che saranno nascosti, come elementi che saranno sovrastati da altri elementi del tutto opachi.
Memorizzazione dei rettangoli in WebKit
Prima di ripitturare, WebKit salva i vecchi rettangoli come bitmap. Poi ripittura solo il delta dei cambiamenti tra i nuovi e i vecchi rettangoli.
Cambiamenti dinamici
Il browser cerca di compiere il minimo delle azioni possibili in risposta ad un cambiamento. Quindi cambiamenti al colore di un elemento richiedono all’elemento interessato di essere ripitturato. Cambiamenti alla posizione dell’elemento causeranno la ridisposizione e la ripittura dell’elemento, dei suoi figli e possibilmente dei suoi parenti. Aggiungere un nodo del DOM causerà la disposizione e la ripittura del nodo. Cambiamenti maggiori, come il cambiamento del font size dell’elemento “ html”, causeranno l’invalidazione delle cache, con conseguente ridisposizione e ripittura dell’intero albero di render.
I threads del motore di rendering
Il motore di rendering ha un unico thread. Quasi tutto, eccetto le operazioni di rete, avvengono in un singolo thread. In Firefox e Safari avviene nel processo principale del browser. In Chrome è il thread principale del processo della tab. Le operazioni di rete possono essere eseguite da diversi threads paralleli. Il numero di connessioni parallele è limitato (solitamente 2-6 connessioni).
Event loop
Il thread principale del browser è un loop di eventi. È un loop infinito che continua a mantenere il processo in vita. Aspetta gli eventi (come quelli di layout e paint) e li processa. Questo è il codice di Firefox per il loop di eventi principale :
|
1 2 |
while (!mExiting) NS_ProcessNextEvent(thread); |
Modello visuale CSS2
Il canvas
Stando alle specifiche CSS2, il termine canvas descrive “lo spazio dove la struttura di formattazione viene renderizzata” : dove il browser pittura i contenuti. Il canvas è infinito in entrambe le direzioni spaziali ma il browser decide una larghezza iniziale basata sulla dimensione del viewport. Stando alle specifiche sullo z-index, il canvas è trasparente se contenuto dentro un altro, e riceve un colore definito dal browser se non lo è.
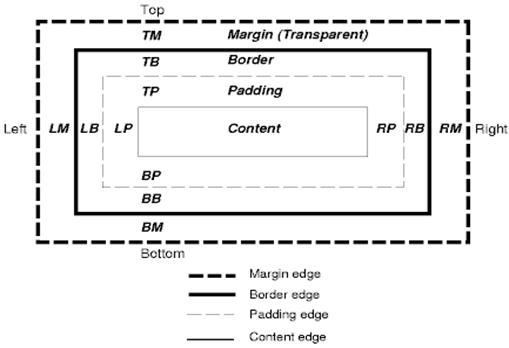
CSS Box model
Il modello CSS a blocchi descrive dei contenitori rettangolari che sono generati per gli elementi nell’albero del documento e sono disposti in base al modello di formattazione visuale. Ogni blocco ha un area di contenuto (e.g. testo, un immagine, etc.) ed aree di ingombri circostanti opzionali quali padding, bordi e margini.
Ogni nodo genera da 0 a n di tali blocchi. Tutti gli elementi hanno una proprietà “display” che determina il tipo di blocco che verrà generato. Esempi :
|
1 2 3 |
block: generates a block box. inline: generates one or more inline boxes. none: no box is generated. |
Il predefinito è inline ma il foglio di stile del browser può impostare altri valori predefiniti. Per esempio : il valore predefinito display per l’elemento “ div” è block. Puoi trovare l’esempio del foglio di stile predefinito qui : http://www.w3.org/TR/CSS2/sample.html
Schema di posizionamento
Ci sono tre schemi :
- Normale: l’oggetto è posizionato in base alla sua ubicazione nel documento. Ciò significa che la sua posizione nell’albero di render è come la sua posizione nell’albero del DOM e viene disposto in base alla sua tipologia di blocco e dimensioni.
- Float: l’oggetto è prima disposto come nel flusso normale, poi viene mosso il più lontano possibile a destra o sinistra.
- Assoluto: l’oggetto è collocato al di fuori dell’albero di render in un posto diverso rispetto al DOM.
Lo scherma di posizionamento è impostato dalla proprietà CSS “ position” e dall’attributo CSS “ float”.
- static e relative causano un flusso normale
- absolute e fixed causano un posizionamento assoluto
Nel caso static non è definito alcun posizionamento e quindi viene usato quello predefinito. Negli altri schemi, l’autore specifica la posizione per mezzo degli attributi top, bottom, left e right. Il modo in cui il blocco viene disposto è determinato da :
- Tipologia del blocco
- Dimensioni del blocco
- Schema di posizionamento
- Informazioni esterne come dimensioni delle immagini e dimensioni dello schermo
Tipi di blocchi
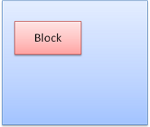
Blocchi block: formano un blocco pieno, con un proprio rettangolo nella finestra del browser.
Blocchi inline : non posseggono un proprio blocco, ma sono contenuti dentro un blocco contenitore.
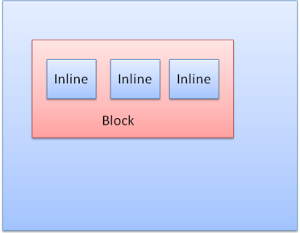
Gli elementi block sono formattati verticalmente uno dopo l’altro, quelli inline sono formattati orizzontalmente.
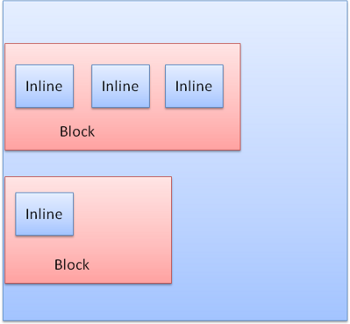
I blocchi inline sono inseriti dentro righe o “blocchi di righe”. Le righe sono alte almeno quanto il più alto dei blocchi ma possono essere più alte, come quando i blocchi sono allineati alla “baseline“, cioè il lato inferiore di un elemento è allineato con un altro elemento ad un punto diverso dal lato inferiore dell’altro. Se la larghezza del contenitore non è sufficiente, gli elementi inline saranno disposti su più righe. Questo è ciò che succede solitamente in un paragrafo.
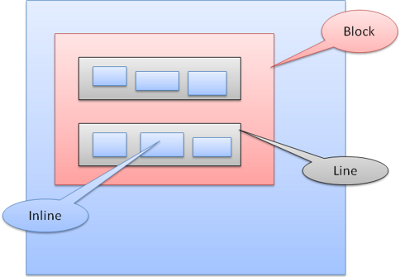
Posizionamento
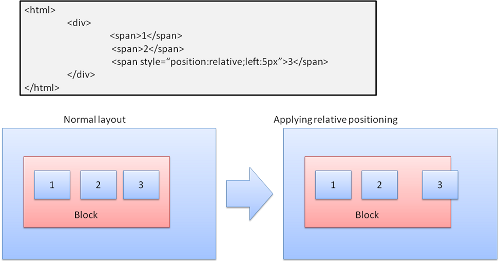
Relativo
Il posizionamento relativo consiste nell’occupare l’ubicazione predefinita che viene poi modifica con il delta richiesto.
Float
Un blocco float viene spostato sul lato destro o sinistro di una riga. La caratteristica interessante è che gli altri blocchi vi scorrono accanto nell’HTML :
|
1 2 3 4 |
<p> <img style="float: right" src="images/image.gif" width="100" height="100"> Lorem ipsum dolor sit amet, consectetuer... </p> |
Apparirà così :

Assoluto e fixed
La disposizione è definita in maniera esatta indipendentemente dal flusso normale. L’elemento non partecipa al flusso normale. Le dimensioni sono relative al contenitore. Nel caso di fixed, il contenitore è il viewport.
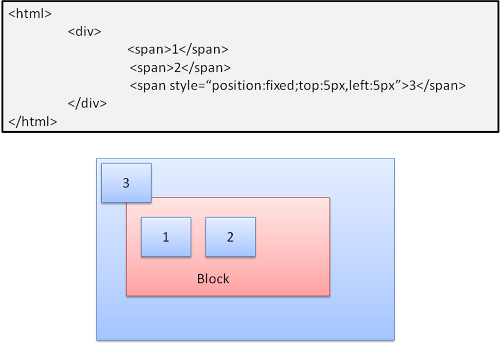
Nota : il blocco fixed non si sposterà neanche quando il documento viene scrollato!
Rappresentazione a livelli
Viene specificata dalla proprietà CSS z-index. Rappresenta la terza dimensione del blocco: la sua posizione lungo l’asse Z. I blocchi sono divisi in catasti (stacks, chiamati stacking contexts). In ogni catasto gli elementi più in fondo vengono pitturati per primi e gli elementi successivi al di sopra, più vicini all’utente. In caso di sovrapposizione l’elemento più avanzato nasconderà l’elemento precedente. I catasti sono ordinati in base alla proprietà z-index. I blocchi con assegnata la proprietà z-index formano un catasto locale. Il viewport possiede il catasto esterno. Esempio :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
<style type="text/css"> div { position: absolute; left: 2in; top: 2in; } </style> <p> <div style="z-index: 3;background-color:red; width: 1in; height: 1in; "> </div> <div style="z-index: 1;background-color:green;width: 2in; height: 2in;"> </div> </p> |
Il risultato sarà questo :

Anche se il div rosso precede quello verde nel codice, e dovrebbe essere pitturato prima nel flusso regolare, la proprietà z-index è superiore, quindi si trova più in alto nel catasto contenuto nel blocco principale.
Risorse
- Architettura dei Browser
- Grosskurth, Alan. A reference Architecture for Web Browsers (pdf)
- Gupta, Vineer. How Browsers Work-Part 1-Architecture
- Parsing
- Aho, Sethi, Ullman, Compilers: Principles, Techniques, and Tools (aka the “Dragon book”), Addison-Wesley, 1986
- Rick Jelliffe. The Bold and the Beautiful: two new drafts for HTML 5.
- Firefox
- L. David Baron, Faster HTML and CSS: Layout Engine Internals for Web Developersv.
- L. David Baron, Faster HTML and CSS: Layout Engine Internals for Web Developers (Google tech talk video)
- L. David Baron, Mozilla’s Layout Engine
- L. David Baron, Mozilla Style System Documentation
- Chris Waterson, Notes on HTML Reflow
- Chris Waterson, Gecko Overview
- Alexander Larsson, The life of an HTML HTTP request
- WebKit
- David Hyatt, Implementing CSS(part 1)
- David Hyatt, An Overview of WebCore
- David Hyatt, WebCore Rendering
- David Hyatt, The FOUC Problem
- Specifiche W3C
- Istruzioni per la build dei browser
 Tali Garsiel è una sviluppatrice in Israele. Ha iniziato come sviluppatrice web nel 2000, ed ha conosciuto il malvagio modello a livelli di Netscape. Come Richard Feynmann, ha sempre avuto la passione di scoprire come funzionano le cose, così ha iniziato a scavare nelle profondità dei browser documentando ciò che ha trovato. Tali ha inoltre pubblicato una breve guida sulle prestazioni client-side.
Tali Garsiel è una sviluppatrice in Israele. Ha iniziato come sviluppatrice web nel 2000, ed ha conosciuto il malvagio modello a livelli di Netscape. Come Richard Feynmann, ha sempre avuto la passione di scoprire come funzionano le cose, così ha iniziato a scavare nelle profondità dei browser documentando ciò che ha trovato. Tali ha inoltre pubblicato una breve guida sulle prestazioni client-side.
 Paul Irish è uno sviluppatore front-end che ama il web. Si occupa di rendere gli sviluppatori più produttivi attraverso strumenti che migliorano il flusso di lavoro ed aiutano a creare siti web mobile e webapp più efficienti. È un sostenitore di Google Chrome. Sviluppa strumenti come Modernizr, Yeoman, HTML5 Please, CSS3 Please, e molti altri progetti open source. È raggiungibile su twitter, IRC, G+ ed il suo blog.
Paul Irish è uno sviluppatore front-end che ama il web. Si occupa di rendere gli sviluppatori più produttivi attraverso strumenti che migliorano il flusso di lavoro ed aiutano a creare siti web mobile e webapp più efficienti. È un sostenitore di Google Chrome. Sviluppa strumenti come Modernizr, Yeoman, HTML5 Please, CSS3 Please, e molti altri progetti open source. È raggiungibile su twitter, IRC, G+ ed il suo blog.